 Process
Analysis Toolkit (PAT) 3.5
Help Process
Analysis Toolkit (PAT) 3.5
Help |
Linearizability is an important correctness criterion for implementations of
objects shared by concurrent processes, where each process performs a sequence
of operations on the shared objects. Informally, a shared object is
linearizable if each operation on the object can be
understood as occurring instantaneously at some point, called the
linearization point, between its invocation and its response, and its
behavior at that point is consistent with the specification for the
corresponding sequential execution of the operation. One common strategy for
proving linearizability of an implementation (used in manual proofs or automatic
verification) is to determine linearization points in the implementation of all
operations and then show that these operations are executed atomically at the
linearization points. However, for many concurrent algorithms, it is difficult
or even impossible to statically determine all linearization points.
Especially, it is extremely hard and trivial for this to be the
users' responsibility to specify such a linearization points. While in our work, we proposed a new method- which is already integrated in
PAT, for automatically checking linearizability based on refinement relations
from abstract specifications to concrete implementations. There is no need
for you to have any knowledge on specifying linearization points. And
if you can give out such information, PAT can definitely take advantage of
them to be much faster and more precise. Our method is complete and sound with
carefully manual proving, as well as efficient due to optimization methods
and the sufficient experiments. For more information please refer to our paper
[LIUWLS09]. As to linearizability as refinement relation, we should first look
into an operation of a process on a shared object. In general, such an operation
has three major actions: the invocation action of object, the linearization
action(compute based on the sequential specification of the object) and the
response action, we will have a clear example in the following part. These
actions can be view as high level actions compared with the concept of low level
actions such as when reading a certain variable, the low level action is to find
the certain position pf the variable, while the high level actions only cares
about such read and response action. Thus we will have a refined
specification to the detailed implemention of model, which only has the
major sequence of events which will potentially contain a linearization
point. Above, we have explored a bunch of ideas including linearizability,
linearization point and linearizability as refinement relation. Instead of
keeping telling massive concepts, we will explore an simple example named
K-valued single-writer single-reader register (PAT examples->
Linearizability Examples-> the first one) to see be aware of these ideas. The implementation of this algorithm is modeled as follows: Note: The Reader process first does a upward scan from element 0 to the
first non-zero element i, and then does a downward scan from element i -1
to element 0 and returns the index of last element whose value is 1. Event
read_res.v returns this index as the return value of the read operation. The
Write(v) process first sets the v-th element of B to 1, and then does a downward
scan to set all elements before i to 0. Note that in this implementation, the
linearization point for Reader is the last point where the parameter v in
DownScan process is assigned in the execution. Therefore, the linearization
point can not be statically determined. Instead, it can be in either UpScan or
DownScan. The abstract mode will be like the following with low-level actions
hided: Note: The ReaderA process repeatedly reads the value of register R and
stores the value in local variable M. Event read_res.M returns the value in M.
WriteA(v) writes the given value v into R. Event write_inv.v stores the value v
to be written into the register. The WriterA process repeatedly writes a value
in the range of 0 to K -1. External choices are used here to enumerate all
possible values. RegisterA interleaves the reader and writer processes and hides
the read and write events (linearization actions). The only visible events are
the invocation and response of the read and write operations. This model
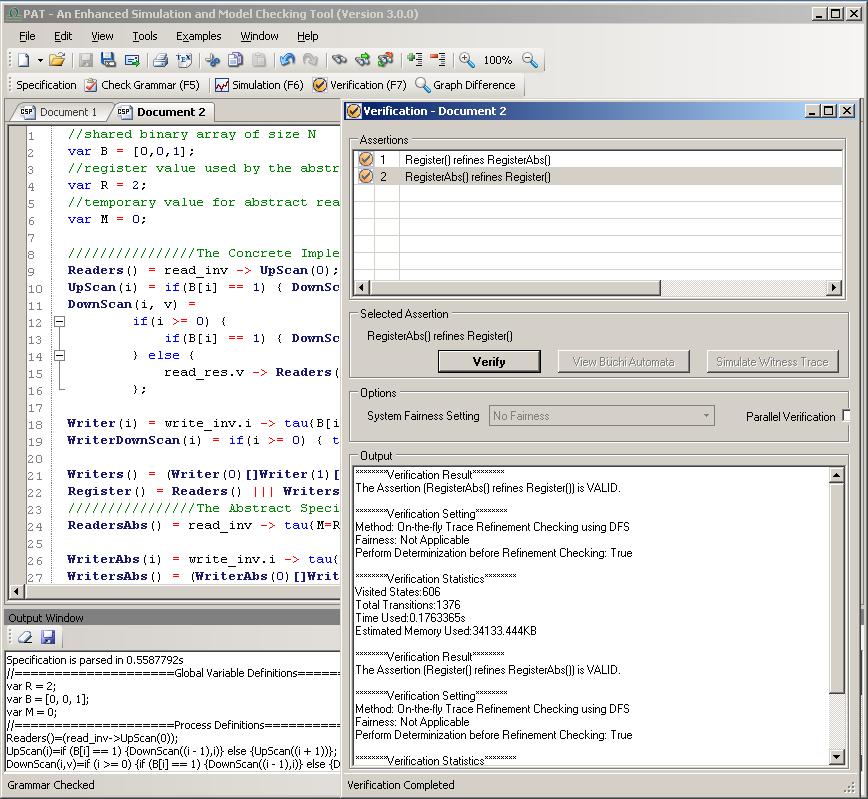
generates all the possible linearizable traces. Thus, we can going to check the refinement relations between the detailed
model and the abstract model to verify the linearizability of K-valued
single-writer single-reader register algorithm.
Copyright © 2007-2012 Semantic Engineering Pte. Ltd.